Based on a review of extant research combined with scoping of datasets digital assets are to be split into three types (communications, records and representations) and four classes of attribute (physical, content, context, and semantic). A series of scoping studies are being undertaken around communication in a large systems engineering project, the digital assets associated with a Formula Student project and the workflow of an in-service repair and maintenance department.
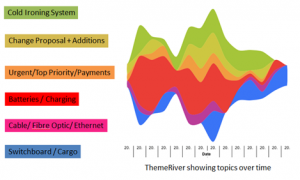
We’ve also begun exploring visualisations of the outputs – here is a ‘theme river’ showing how various key topics from a project wax and wane over the lifetime of a project – all extracted automatically:
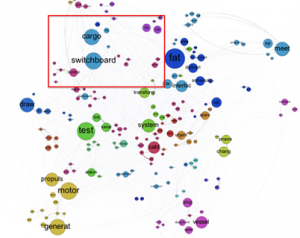
And here is an example of an automatic analysis of how terms used in a project are related to each other – this could be used to help uncover hidden dependencies, for example: